Basketball analytics has transformed the way teams strategize and evaluate performance. In this project, we explored shot success prediction using NBA shot location data from 2003 to 2024. Leveraging advanced machine learning techniques, we uncovered key insights that could inform player development and game strategies. For more details and to explore the code, visit the project repository on: GitHub
#Project Scope and Dataset
Our dataset combined:
- Shot Data: Over 4 million records detailing shot types, distances, zones, and outcomes.
- Player Data: Comprehensive player profiles, including positions, experience, and rosters.
- Team Data: Information about all active NBA teams.
To ensure data integrity:
- Cleaned and validated records using fuzzy matching (e.g., Qgram-Jaccard).
- Filtered for active players and teams using NBA's API.
The refined dataset of 1.3 million records became the foundation for our analysis.
#Exploratory Data Analysis (EDA)
Using tools like Seaborn and Plotly, we analyzed the factors influencing shot success:
- Distance Matters: Shorter shots (e.g., within 8 ft.) had higher success rates.
- Shot Types Differ: Dunks were most accurate, while jump shots had lower probabilities.
- Game Context: Accuracy dropped in later quarters, and players performed better during home games.
Heatmaps and visualizations provided actionable insights into player and team performance trends.
#Advanced Modeling Techniques
#Dimensionality Reduction with PCA
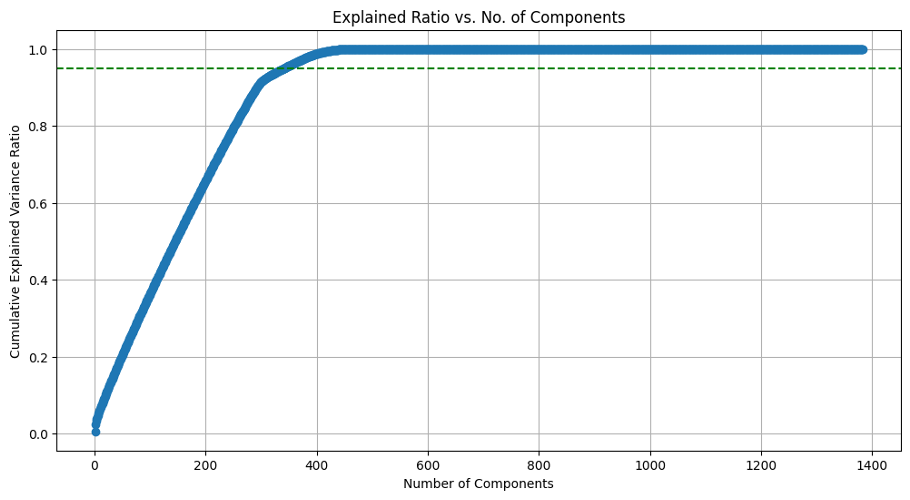
To handle the dataset's high dimensionality, we applied Principal Component Analysis (PCA), reducing features from over 1,300 to 350 while preserving variance.
#Machine Learning Models
We tested several algorithms, including:
- Tree-Based Models: Random Forests and Gradient Boosting.
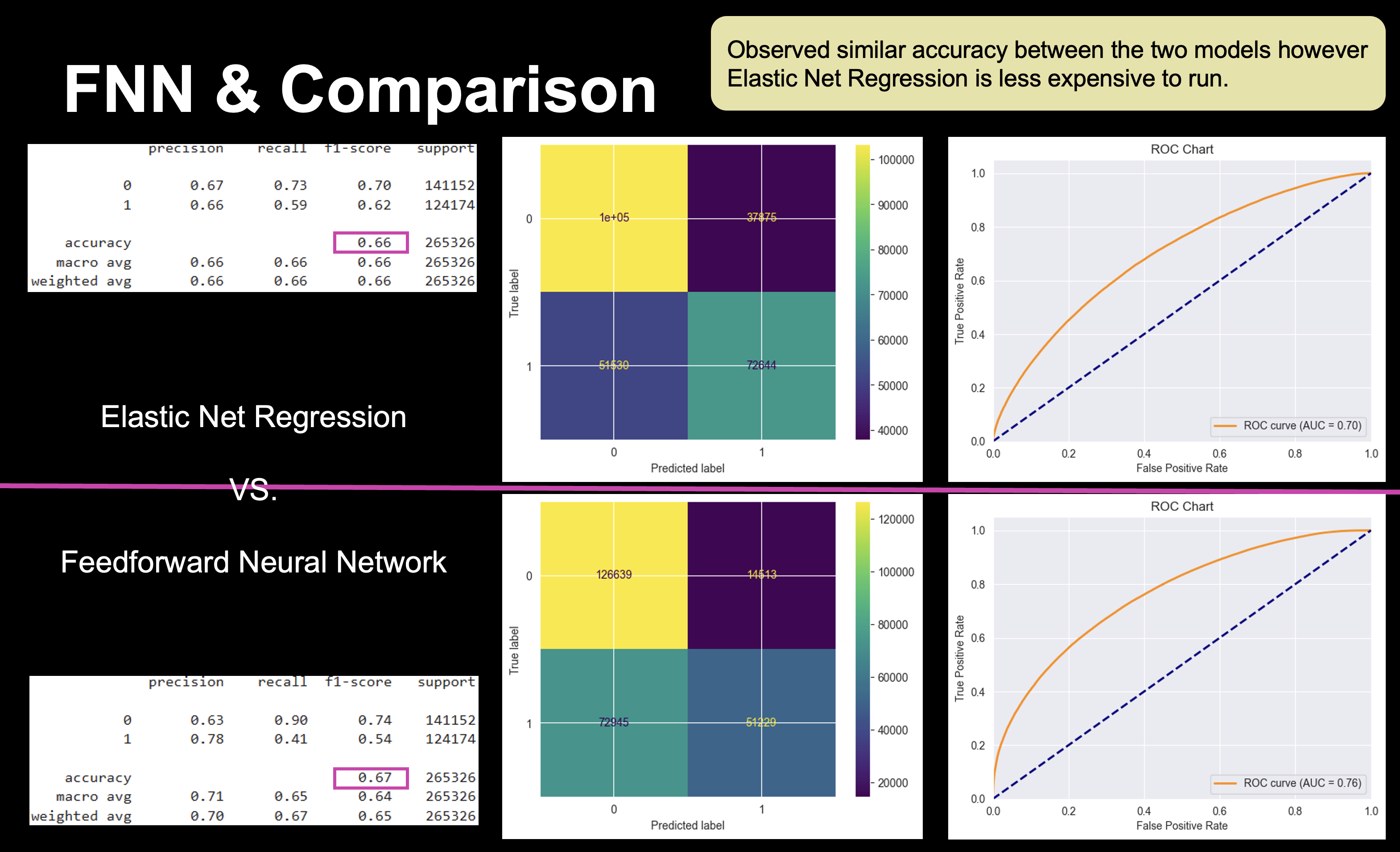
- Elastic Net Logistic Regression: Chosen for its balance of speed and accuracy (~66%).
- Feedforward Neural Networks (FNNs): Achieved similar accuracy but required more computational resources.
#Feed Forward Neural Network Architecture
class FNN(nn.Module):
def __init__(self, input_dim, rnn_hidden_dim, rnn_layer_dim):
super(FNN, self).__init__()
self.rnn_hidden_dim = rnn_hidden_dim
self.rnn_layer_dim = rnn_layer_dim
self.rnn = nn.RNN(input_dim, rnn_hidden_dim, rnn_layer_dim, batch_first=True, nonlinearity='relu')
self.linear_relu_stack = nn.Sequential(
nn.Linear(rnn_hidden_dim, 1024),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Dropout(p=0.4),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(p=0.35),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(p=0.2),
nn.Linear(64, 32),
nn.ReLU(),
nn.Dropout(p=0.15),
nn.Linear(32, 1)
)
def forward(self, x):
x = x.unsqueeze(1)
h0 = torch.zeros(self.rnn_layer_dim, x.size(0), self.rnn_hidden_dim).to(x.device)
out, hn = self.rnn(x, h0.detach())
rnn_features = out[:, -1, :]
output = self.linear_relu_stack(rnn_features)
return output#ML Model Selection and Evaluation
%time
x_train_subset_svd, _, y_train_subset_svd, _ = train_test_split(x_train_svd, y_train, train_size=subset_size, random_state=42,shuffle=True)
param_grids = {
"DecisionTreeClassifier": {
"max_depth": [None, 10, 20, 30],
"min_samples_split": [2, 5, 10],
"min_samples_leaf": [1, 2, 4],
"criterion": ["gini", "entropy"],
},
"AdaBoostClassifier": {
"n_estimators": [50, 100, 200],
"learning_rate": [0.01, 0.1, 1.0],
},
"GradientBoostingClassifier": {
"n_estimators": [50, 100, 200],
"learning_rate": [0.01, 0.1, 0.2],
"max_depth": [3, 5, 10],
"min_samples_split": [2, 5, 10],
},
"RandomForestClassifier": {
"n_estimators": [50, 100, 200],
"max_depth": [None, 10, 20],
"min_samples_split": [2, 5],
"min_samples_leaf": [1, 2, 4],
},
"ExtraTreesClassifier": {
"n_estimators": [50, 100, 200],
"max_depth": [None, 10, 20],
"min_samples_split": [2, 5],
"min_samples_leaf": [1, 2, 4],
},
"LogisticRegression": {
"C": [0.01, 0.1, 1, 10],
"penalty": ["l2"],
},
"Lasso (Logistic Regression)": {
"C": [0.01, 0.1, 1, 10],
"penalty": ["l1"],
},
"RidgeClassifier": {
"alpha": [0.1, 1.0, 10.0],
"max_iter": [1000, 2000],
},
"ElasticNet (Logistic Regression)": {
"C": [0.01, 0.1, 1, 10],
"penalty": ["elasticnet"],
"l1_ratio": [0.1, 0.5, 0.9],
},
"SVC": {
"C": [0.1, 1],
"kernel": ["rbf"],
"gamma": ["scale"],
},
}
if os.path.exists('best_models.pkl.zip'):
#unzip the file
with zipfile.ZipFile('best_models.pkl.zip', 'r') as file:
file.extractall()
best_models = joblib.load('best_models.pkl')
print("Best Models Loaded")
else:
best_models = {}
for name, model in models:
print(f"Tuning {name}")
param_grid = param_grids.get(name, None)
grid_search = RandomizedSearchCV(model, param_grid, cv=3, scoring=scoring, n_jobs=-1, verbose=1, n_iter=10)
grid_search.fit(x_train_subset_svd, y_train_subset_svd)
best_score_ = grid_search.best_score_
best_params_ = grid_search.best_params_
best_models[name] = (grid_search.best_estimator_, best_params_, best_score_)
print(f"Best parameters for {name}: {best_params_}")
print(f"Best cross-validation score: {best_score_}")
joblib.dump(best_models, 'best_models.pkl')
print("Best Models Saved")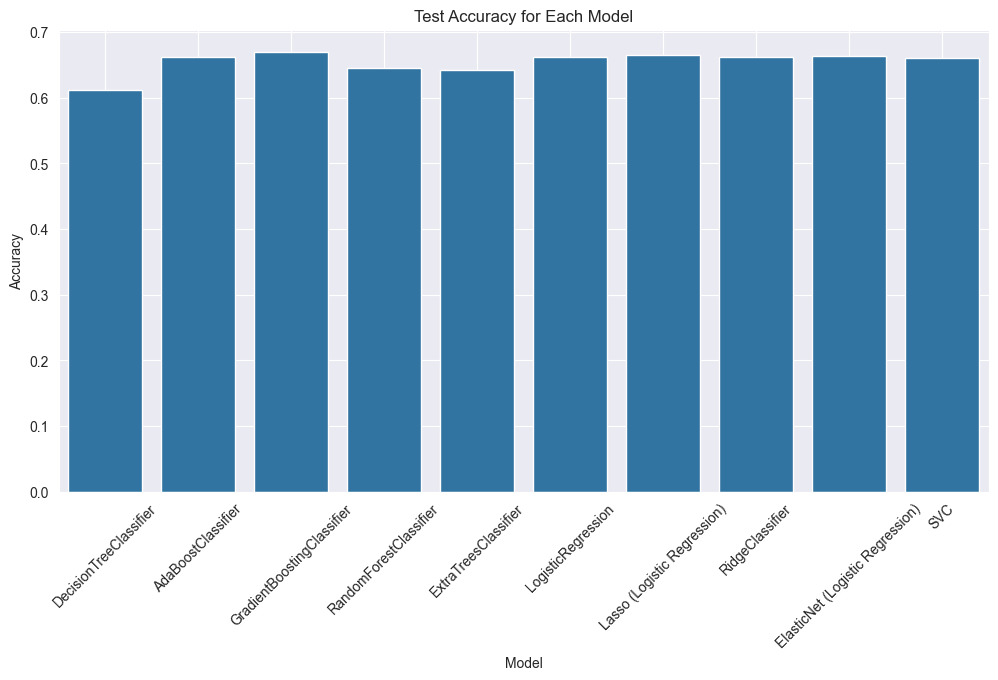
#FNN and Logistic Regression Comparison